OnCall IVR Designer v7.11.2, part of OnCall IVR Suite v3.3.x
Speech Recognition
Speech recognition is a feature that allows the IVR system to understand and process spoken language. It is used to recognize spoken words and phrases and use the recognition result to control the flow of the IVR system.
To enable speech recognition on a node or template, you must define grammar rules that the speech engine will use to recognize spoken words and phrases. These grammar rules are specified in the Grammars management section of the IVR Designer.
Note
The language of the speech recognizer engine can be specified on the Start node of the flow.
Before selecting a language, make sure that the associated language package is installed on the IVR system's speech recognizer engine.
Defining Grammars
To add a new grammar, click the Add grammar icon in the Grammars section. Fill in the input fields in the Add or edit grammar dialog.
The grammar's name should be a unique and descriptive identifier, used for easy identification in the list of grammars.
The content of a grammar is a list of words and phrases that the speech engine will recognize. Each word or phrase should be on a separate line.
The value of the grammar contains the grammar rules in XML form, adhering to the SRGS 1.0 standard.
The defined grammar value is inserted into a template and should start at the rule level, including a primary rule with the id="main" attribute.
An example of a simple grammar definition is shown below:
<rule id="main" scope="public">
<one-of>
<item>
accounting
<tag>out.selected_option="ACCOUNTING";</tag>
</item>
<item>
credit management
<tag>out.selected_option="CREDIT_MANAGEMENT";</tag>
</item>
<item>
other
<tag>out.selected_option="OTHER";</tag>
</item>
</one-of>
</rule>
Caution
All changes made to grammars will be applied permanently only after saving the flow. Closing the flow without saving will result in the loss of all changes made to grammars.
An existing grammar can be edited by clicking the Edit icon next to the grammar in the list. A grammar can be deleted by clicking the Delete icon next to the grammar in the list.
DTMF grammars
In the Grammars section, you can define both voice and DTMF grammars. A DTMF grammar can be used by a DTMF detector to determine sequences of legal and illegal DTMF tones. The grammar is defined in the same way as a voice grammar, but instead of spoken words and phrases, it contains DTMF tokens.
An example of a simple DTMF grammar definition is shown below:
<rule id="main" scope="public">
<one-of>
<item>
1
<tag>out.selected_option="ACCOUNTING";</tag>
</item>
<item>
2
<tag>out.selected_option="CREDIT_MANAGEMENT";</tag>
</item>
<item>
3
<tag>out.selected_option="OTHER";</tag>
</item>
</one-of>
</rule>
Note
The mode of the grammar (speech or dtmf) is determined by the node attribute in which the grammar is used. It is set in the grammar template based on the given node attribute.
Important
A grammar can only be of one mode at a time. Either 'dtmf' type or 'speech' type.
Template of the Grammar
The grammar template is defined in the grammar_template.xml file, located in the .\EndPoint\Templates\ folder within the IVR Engine installation directory.
The default template is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<grammar xmlns="http://www.w3.org/2001/06/grammar" version="1.0" xml:lang="{LANGUAGE_CODE}" mode="{INPUT_MODE}" root="main" tag-format="semantics/1.0">
{INPUT_SRGS_FRAGMENT}
</grammar>
The LANGUAGE_CODE placeholder is substituted with the ISO language code of the selected speech recognizer language package.
Similarly, the INPUT_SRGS_FRAGMENT placeholder is replaced with the grammar value defined in the IVR Designer.
The INPUT_MODE placeholder is replaced with the mode of the grammar (speech or dtmf).
A final grammar is going to look like this:
<?xml version="1.0" encoding="UTF-8"?>
<grammar xmlns="http://www.w3.org/2001/06/grammar" version="1.0" xml:lang="en-US" mode="voice" root="main" tag-format="semantics/1.0">
<rule id="main" scope="public">
<one-of>
<item>
accounting
<tag>out.selected_option="ACCOUNTING";</tag>
</item>
<item>
credit management
<tag>out.selected_option="CREDIT_MANAGEMENT";</tag>
</item>
<item>
other
<tag>out.selected_option="OTHER";</tag>
</item>
</one-of>
</rule>
</grammar>
Using speech recognition in the flow
When a node with speech recognition (PromptSR, PromptJumpSR) is executed, the outcome of the speech recognition is stored in the srresult variable. The srcompletioncode variable contains the completion code of the speech recognition operation.
The srcompletioncode variable can take on the following number values, corresponding to the MRCPv2 Completion-Cause:
srcompletioncode value |
Cause-Code | Cause-Name |
|---|---|---|
| 0 | 000 | success |
| 1 | 001 | no-match |
| 2 | 002 | no-input-timeout |
| 3 | 003 | hotword-maxtime |
| 4 | 004 | grammar-load-failure |
| 5 | 005 | grammar-compilation-failure |
| 6 | 006 | recognizer-error |
| 7 | 007 | speech-too-early |
| 8 | 008 | success-maxtime |
| 9 | 009 | uri-failure |
| 10 | 010 | language-unsupported |
| 11 | 011 | cancelled |
| 12 | 012 | semantics-failure |
| 13 | 013 | partial-match |
| 14 | 014 | partial-match-maxtime |
| 15 | 015 | no-match-maxtime |
| 16 | 016 | grammar-definition-failure |
When speech recognition is unsuccessful, the srresult variable contains a null value.
When the speech recognition operation is successful (indicated by the srcompletioncode variable value of 0 for success), the srresult variable contains a JSON object representing the recognition result in NLSML format. The JSON object has the following schema:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"interpretations": {
"type": "array",
"description": "Array of interpretations of the recognized speech. Each interpretation contains the confidence level and recognized instances of the spoken words or phrases.",
"items": {
"type": "object",
"properties": {
"confidence": {
"type": "integer",
"description": "Confidence level of the interpretation, ranging from 0 to 100."
},
"instances": {
"type": "object",
"description": "Object representing the data of the instance.",
"patternProperties": {
"^[a-zA-Z0-9_]+$": {
"type": "string"
}
},
"additionalProperties": false
},
"inputMode": {
"type": "string",
"enum": ["speech", "dtmf"],
"description": "The modality of the input. Optional."
},
"inputText": {
"type": "string",
"description": "The recognized input text. Optional."
}
},
"required": ["confidence", "instances", "inputMode", "inputText"],
"additionalProperties": false
}
}
},
"required": ["interpretations"],
"additionalProperties": false
}
A simple example of the srresult variable value is shown below:
{
"interpretations": [
{
"confidence": 90,
"instances": {
"selected_option": "ACCOUNTING"
},
"inputMode": "speech",
"inputText":"accounting"
}
]
}
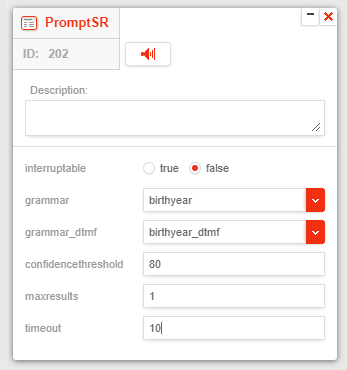
PromptSR node
The PromptSR node is used to prompt the caller and collect some data via speech or DTMF based on grammar.
The PromptSR node has the following parameters:
- interruptable - If set to true, the caller can interrupt the prompt by speaking or pressing DTMF keys. If set to false, the caller cannot interrupt the prompt.
- grammar - The voice grammar that the speech engine will use to recognize the spoken word or phrase.
- grammar_dtmf - Optional. The DTMF grammar that the speech engine will use to recognize the pressed DTMF keys.
- confidencethreshold - The confidence level that the speech engine will use to determine if the spoken word or phrase matches the grammar.
- maxresults - The maximum number of recognized words or phrases that the speech engine will return.
- timeout - The time in seconds that the speech engine will wait for the caller to speak or press DTMF keys before timing out.
The PromptSR node has the following output transitions:
- next - The flow will proceed to this transition if the speech engine recognizes the spoken word or phrase, or the pressed DTMF keys, or returns a valid completion cause (e.g., 001 no-match).
The
srcompletioncodeandsrresultvariables are set after this transition. - error - The flow will proceed to this transition if the speech recognition operation fails or if other errors occur.
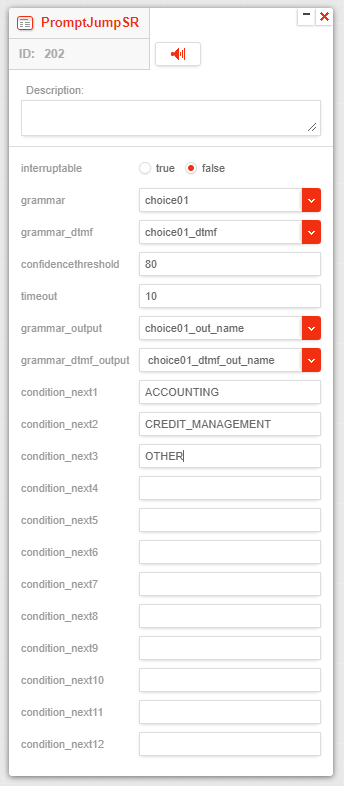
PromptJumpSR node
The PromptJumpSR node is used to prompt the caller to select an option via speech or DTMF based on grammar. The flow will jump to the next node associated with the selected option.
The PromptJumpSR node has the following parameters:
- interruptable - If set to true, the caller can interrupt the prompt by speaking or pressing DTMF keys. If set to false, the caller cannot interrupt the prompt.
- grammar - The voice grammar that the speech engine will use to recognize the spoken word or phrase.
- grammar_dtmf - Optional. The DTMF grammar that the speech engine will use to recognize the pressed DTMF keys.
- confidencethreshold - The confidence level that the speech engine will use to determine if the spoken word or phrase matches the grammar.
- timeout - The time in seconds that the speech engine will wait for the caller to speak or press DTMF keys before timing out.
- grammar_output - A variable which holds the name of the voice grammar output that needs to be evaluated to determine the next node.
- grammar_dtmf_output - Optional. A variable which holds the name of the DTMF grammar output that needs to be evaluated to determine the next node. It has to be used in conjunction with the
grammar_dtmfparameter. - [condition_next1 | condition_next2 | .. | condition_next12] - The value of the grammar output that will cause the flow to jump to the [next1 | next2 | .. | next12] transition.
The PromptJumpSR node has the following output transitions:
- [next1 | next2 | .. | next12] - The flow will proceed to this transition if the speech engine recognizes the spoken word or phrase or if DTMF keys are pressed, and the grammar output matches the value of [condition_next1 | condition_next2 | .. | condition_next12].
- nextnocondition - The flow will proceed to this transition if the speech engine recognizes the spoken word or phrase or pressed DTMF keys, but the grammar output does not match any of the specified conditions.
- nextelse - The flow will proceed to this transition if the speech engine fails to recognize the spoken word or phrase, if DTMF keys are pressed, or if a valid completion cause is returned (e.g., 001 no-match).
- error - The flow will proceed to this transition if the speech recognition operation fails or if other errors occur.